텍스트마이닝을 이용한 금연 홍보 웹툰의 반응분석: “씌가렛뎐” 댓글을 중심으로
Response Analysis of Stop Smoking Campaign Webtoon Using Text Mining Technology: Focused on the “Tale of Cigarette” Comments
Article information
Trans Abstract
Objectives
Recently, webtoons have been developed through a variety of fields’ advertisement platforms as well as non-smoking campaign. However, the only way to evaluate the effect of brand webtoons is limited to ratings, comments, and page views so far. Our research analyzed smoking cessation advertising brand webtoon’s comments by using text mining method.
Methods
We chose the “Tale of Cigarette” webtoon which was well known as a cartoon for non-smoking campaign. Its rating was 9.91 rated by 107,264 readers. We analyzed the association between frequent morpheme and morpheme, and also analyzed sentiments embedded in user comments. A total of 20,560 comments were manually exported from Naver webtoon site and 18,117 comments were used for morpheme analysis and sentiment analysis.
Results
Frequent morpheme analysis results showed that the ‘cigarette’ was most frequent, and was followed by other words such as ‘smoking cessation’, ‘human’, ‘smoker’, ‘dad’, ‘please’, ‘smoking’ in ranking. Comments were converted through transaction for association analysis. Support, confidence and lift were applied to the transaction data to check for association patterns, and results showed high lifts between the word ‘cigarette’ and words ‘smoking’, ‘tax’, ‘street’, ‘smell’, and ‘smoke’. Sentiment analysis results showed that negative sentiment in the early episodes changed into positive sentiment as the episodes progressed.
Conclusions
Our results showed that the webtoon was an effective media as a non-smoking campaign. In order to successfully advertise smoking cessation through brand webtoon, it was important to convince the users and make them understand the harmful effects of smoking. In addition, it was equally important to ultimately make them quit through repeated publishing, and to attract them to smoking cessation related topics.
서 론
흡연은 전 세계적으로 주요 사망 원인 중 하나이다. 세계보건기구(World Health Organization, WHO)에 따르면 전 세계적으로 대략 600만 명이 흡연으로 인해 사망한다[1]. 국제 암연구소(International Agency for Research on Cancer)는 현재 담배 연기를 1급 발암 물질로 분류하고 있다[2]. 34개 경제협력개발기구(Organization for Economic Cooperation and Development, OECD) 회원국 중 우리나라의 15세 이상 인구 중 남자 흡연율은 2순위로 높은 흡연율을 보이고 있다[3]. 최근 들어 확산되고 있는 전자담배의 경우 청소년 경험률이 14.5%, 여학생은 3.3%로 남학생에서 약 4배 정도 높게 나타나고 있다[4,5].
흡연 예방 프로그램은 사용자들의 특성에 맞게 다양한 매체를 사용하여 설계되어야 한다. Chun and Kim [6]은 국내에서 실시되고 있는 청소년 흡연 예방 및 금연 프로그램과 연구에 대한 전반적인 경향을 분석하였고, 표준화된 모델 프로그램의 개발의 필요성과 보다 정교한 이론적 틀을 가진 연구 설계를 가지고 효과성을 검증하며 이를 바탕으로 임상 현장에 증거기반 실천의 근거를 제공해야 한다고 하였다. 해외에서는 SNS, 인터넷 동영상 스트리밍 서비스(streaming service) 등을 이용한 담배에 대한 규제와 온라인 금연 교육의 필요성이 제기되고 있다[7]. 국내에서도 온 ·오프라인으로 다양한 금연 홍보가 진행되고 있으며, 그 중 2014년 보건복지부의 금연 홍보의 일환으로 제작된 웹툰(webtoon) <씌가렛뎐>은 많은 독자들에게 좋은 반응을 보이며 네이버 웹툰에서 총 12화를 연재하였다.
웹툰은 1990년대 후반부터 활성화되었으며 웹툰이 새로운 홍보 수단으로 대두되었으나 그 효과의 분석을 다룬 연구는 부족하다. 이는 전통적인 설문방식으로 웹툰의 효과를 검증하기 어렵기 때문이다. 본 연구의 대상인 <씌가렛뎐>은 <자유부인>이라는 이름으로 네이버 베스트도전에 137화를 연재를 하였던 데니코 작가(강무선)가 제작하였으며, 개화기 한양의 담배에 중독된 자유부인과 그녀의 몸종이 흡연으로 인해 건강이 악화되는 것을 느끼게 되어 금연 결심을 하게 되었고, 금연 클리닉의 도움을 받아 성공을 한다는 내용이다. 그동안 딱딱한 내용의 금연 홍보가 재미있는 내용으로 큰 성공을 거두었으며, 이는 2015년에 5,000만 건의 조회수를 기록한 <본격금연권장만화>라는 작품이 제작된 계기가 되었다. 웹툰의 댓글은 작가와 독자 간의 의사소통을 하는 일종의 매개체 역할을 하고 있다. 작가는 댓글을 통하여 독자들의 의견을 받을 수 있고, 독자들은 소감을 표출하며, 해당 웹툰에 대한 홍보 역할을 하게 되므로 댓글은 중요한 electronic word of mouth (eWOM) 방법이라고 할 수 있다. 최근 들어 모바일 스마트 기기의 증가로 댓글의 가시성은 더욱 증가하여 다른 WOM 매체보다 더욱 영향력이 크다[8].
기존의 댓글 분석에 대한 연구는 댓글의 비정형성으로 인해서 연구는 거의 전무한 실정이다. 특히 보건 건강 관련 매체가 지속적으로 출시되고 있으나 댓글에 대한 연구는 없었다. 본 연구에서는 금연 홍보를 위한 브랜드 웹툰의 댓글을 텍스트 마이닝(text mining) 기법을 이용하여 다빈도 형태소와 형태소 간의 연관관계를 통하여 독자들이 댓글에 쓰는 의견에 대하여 분석하고, 댓글의 감성을 긍정·부정·중립으로 나누어 분석을 하려고 한다. 이를 통해 웹툰이 연재되면서 댓글의 감성 변화나 다빈도 형태소가 변하는 것을 관찰하며, 금연 브랜드 웹툰에 대한 반응을 알아보고자 한다. 또한 웹툰을 주로 구독하는 사용자들의 금연에 대한 반응 정도를 댓글을 통하여 알아보고, 웹툰 플랫폼을 통한 금연 홍보에 대한 반응을 시각적으로 표현하여 금연 홍보 플랫폼으로서 그 가능성을 알아보고자 한다.
이론적 배경
브랜드 웹툰
보건복지부, 한국건강증진개발원, 국가금연지원센터에서는 최근 청소년들의 흡연이 증가하면서 다양한 학교 흡연 예방 교육을 시행하고 있으며, 청소년에게는 인기 아이돌 멤버를 주연으로 하여 웹드라마를 제작하여 홍보영상으로 사용하고 있고 재미와 관심을 가질 수 있는 다양한 교육 자료를 개발하고 있다[6]. 그 외에도 한국건강관리협회의 ‘청소년 금연짱’, 청소년 금연금주 상담센터, 한국 금연 교육원 등 다양한 기관에서 청소년 금연 교육에 노력을 하고 있다. 그러나 이러한 금연 교육에 대한 효과에 관한 연구는 부족한 편이다. 청소년 흡연은 내적인 심리적 특성과, 사회 환경적 특성에 따른 요인으로 구분되어진다.
브랜드 웹툰은 기업이나 공공기관에서 서비스, 상품, 정책 또는 브랜드의 이미지 등을 널리 알리기 위해 만화를 일종의 광고 수단으로 활용하는 경우를 일컫는다. 최근 등장하고 있는 브랜드 웹툰은 홍보와 창작의 경계를 무너뜨리고 하나의 독립된 콘텐츠로 거듭하고 있다. 현재 네이버 웹툰에는 연재중이거나 연재를 완료한 브랜드 웹툰이 100개 이상이며 작가의 인기도에 따라서 브랜드 웹툰도 함께 인기가 있는 것을 알 수 있다.
웹툰은 Web 2.0을 기반으로 일방적이 아닌 쌍방향의 의사소통이 가능한 다양한 형태의 온라인 커뮤니티가 형성되어 인터넷을 통해 의사소통이 가능하다. 대중들은 댓글을 통해 자신들의 의견을 표현할 수 있게 되면서 댓글은 온라인 여론 형성에 중요한 역할을 하고 있고 관련 연구도 증가하고 있다[9]. 브랜트 웹툰의 증가에 비하여 댓글에 관한 연구는 매우 부족한 실정이며, 특히 텍스트 마이닝과 같은 빅데이터(big data) 분석기법을 이용하여 웹툰 댓글을 분석한 국내 논문은 전무하였다.
데이터 마이닝과 텍스트 마이닝
텍스트 마이닝은 데이터 마이닝(data mining)의 여러 방법 중 비정형 분석 방법이다. 데이터 마이닝은 대규모로 저장된 데이터에서 체계적이고 자동적으로 규칙이나 패턴을 찾아내는 것이다. 데이터 마이닝은 패턴 인식에 이르는 다양한 계량 기법을 사용한다. 탐색적 자료분석, 가설 검정, 다변량 분석, 시계열 분석, 일반선형모형 등의 방법론과 데이터베이스 쪽에서 발전한 on-line analytic processing (OLAP), 인공지능에서 발전한 self organizing map (SOM), 신경망, 전문가 시스템, 의사결정나무 등의 기술적인 방법론이 쓰인다. 텍스트 마이닝은 비정형 데이터를 정형화된 데이터로 변환시켜 분석하여 의미 있는 패턴과 관계를 찾고 이를 추출하는 일련의 과정이다. 비정형 텍스트 데이터들을 구분하여 이들 간의 연관성을 찾아 데이터를 클러스터링, 구조적 데이터와 결합을 통해 모델 구축 등을 수행한다.
텍스트 마이닝 과정은 크게 3단계의 과정을 거친다[10]. 첫 번째로 비정형 데이터의 수집으로 웹사이트, 이메일, 문서 같은 비정형 데이터에서 문장의 단어, 규칙 등의 연관성을 고려하는 연관성 분석에 의해 관심 단어 후보를 만들어 내는 과정이다. 두 번째로 전처리 과정은 앞서 추출된 텍스트의 내용에 따라 문서들을 범주화시켜주는 과정으로써 문서 유사도에 의한 방법과 정보 검색에 기반을 두는 방법 등이 있다. 비정형 데이터를 구조화된 데이터로 변경을 하는 과정이다. 세 번째로 설명 및 예측 기법을 적용하여 문서 내에 추출된 형태소들을 유사도에 따라 여러 개의 그룹으로 군집화를 하는 과정이다. 군집화 된 그룹의 정보를 공유하여 문서들의 유사도를 파악하고 도표화 및 분류화를 하여 유용한 정보를 추출하는 과정이다.
Lee et al. [11]은 영화 흥행 예측 분석을 연구하였다. 영화 흥행 여부를 종속변수로 하고, 댓글, 리뷰 등을 정제하여 영향 있는 형태소를 추출하여 분석 연구한 결과 평점 평균보다 텍스트 마이닝을 통한 분석이 더 유의하다고 하였다. Kam and Song [12]은 텍스트 마이닝을 활용한 신문사에 따른 내용 및 논조 차이점을 분석하여 신문 기사들의 전반적인 내용과 논조에 차이가 있다고 하였다.
감성 분석은 텍스트에 나타난 사람들의 태도, 의견, 성향과 같은 주관적인 데이터를 분석하는 자연어 처리 기술로써 2012년 미국 대선에서 이 기법이 이용되면서 그 인기가 상승하였다. 소셜미디어에서 감성 분석은 여론 분석을 위해 수집된 소셜미디어 빅데이터를 바탕으로 각각의 문서가 긍정, 부정, 중립 중에서 어떤 감성 분류에 속하는지 감성 점수를 계산하는 방법으로 분류하는 것을 말한다[13,14]. Kang and Song [15]은 소셜네트워크서비스의 감성 분석을 이용하여 의료기관의 고객만족도 평가모형에 관한 연구를 진행하였다. 국내 5개 대형병원의 평판과 감성 분석을 적용하여 각 병원마다 특성이 있고 개선해야 하는 항목이 다르다는 것을 연구하였다.
연구 방법
연구대상 및 자료 수집 방법
본 연구는 2014년 11월 3일부터 2015년 1월 19일까지 네이버 웹툰에서 연재된 강무선 작가의 ‘씌가렛뎐’의 댓글을 대상으로 하였다. 댓글은 2014년 11월 3일부터 2015년 10월 31일까지 웹툰에 등록된 20,560건 중에 데이터 전처리 작업 후 18,117건에 대한 댓글을 대상으로 하였다. 데이터 전처리 작업은 Figure 1과 같이 먼저 의성어(ㅋㅋ, ㅎㅎ 등), 의미없는 단순 숫자(댓글 순위 놀이 1, 1등), 이모티콘(^^, ㅇ.ㅇ; 등), 욕설, 같은 아이디로 쓴 중복된 댓글인 총 2,443건의 댓글을 삭제한 후 18,117건의 댓글을 통해 분석에 사용하였다.
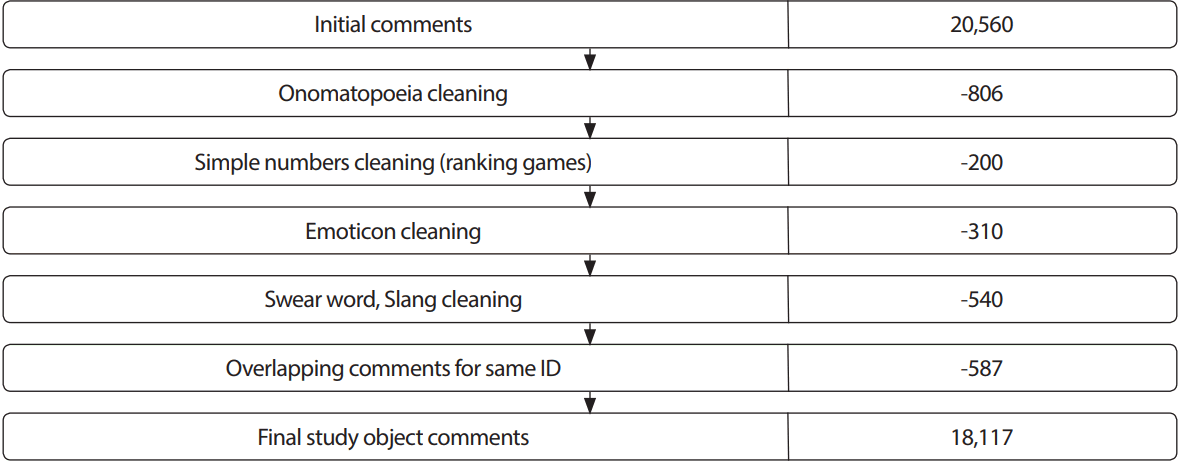
Preprocessing of comments.
자료 수집
분석을 원하는 대상에 대해서 R 프로그램이나 크롤링을 이용한 자동 수집을 하지만 본 연구 대상인 네이버 웹툰은 검색 로봇에 의한 문서 수집이 불가능하여 전체 댓글을 수작업으로 수집하였으며 댓글 하나를 한 문단으로 처리하였다.
형태소 분해
‘말의 가장 작은 단위’인 형태소를 분해하였다. 다양한 형태소 분해 알고리즘이 있으나, 여러 연구에서 많이 사용하는 Semantria와 R의 Sejong라이브러리를 사용하여 분해를 하였다.
형태소 출현 빈도 계산
형태소가 얼마나 자주 출현했는지 출현 빈도를 계산하였다. 모든 형태소를 분석을 하는 것은 일반 PC의 성능으로는 한계가 있으므로 일반적으로 상위 60-100위 출현 형태소로 분석대상을 줄인다. 본 연구에서는 최초 상위 100위를 분석하는 방법을 사용하였다.
형태소 간 연관 관계 분석
연관성 규칙은 형태소 간의 관계를 살펴보고 유용한 규칙을 찾아내고자 할 때 이용되는 기법으로 본 연구에서는 연관 정도를 정량화하기 위해서 지지도(Support), 신뢰도(Confidence), 향상도(Lift)를 계산하였다. 지지도는 항목 사이에서 동시에 포함하는 빈도가 어느 정도인지를 나타낸다. 신뢰도는 연관성 규칙의 강도를 조건부 확률로 나타낼 수 있다.
향상도는 형태소 X가 있는 경우 형태소 Y가 있는 경우와 Y가 X와 상관없이 나타난 비율을 나타낸다. 향상도가 1이면 상호 독립적이며 1보다 크면 양의 상관관계 1보다 작으면 음의 상관관계를 나타낸다.
또한 동시 단어 출현 분석 방법을 사용하여 형태소 간 관계를 시각화 하였다. 컴퓨터로 한 문장에서 동시에 출현한 단어 간 관계를 상관계수 행렬 등으로 변화하고, 이때 각 형태소는 수치형 자료에서 변수의 형태로 변환되어 형태소의 개수와의 상관관계를 도출할 수 있게 하였다.
데이터 분석 및 도식화
연관관계의 행렬을 얻은 후 군집 분석(cluster analysis)과, 사회 네트워크 분석(social network analysis) 기법을 이용하여 분석하였다. 사회 네트워크 분석을 사용하면 단어 간 네트워크 구조를 볼 수 있다. 또한 동시에 단어 집합의 중요성을 그림으로 직관적으로 알 수 있다. 본 연구에서는 18,117건의 댓글에서 183,708개의 형태소 간의 연관 관계성을 파악하여 금연 브랜드 웹툰 댓글이 어떤 구조로 구성되어 있는지 파악하였다.
감성 분석
수집한 데이터로부터 감성 분석을 적용할 부분만을 추출하는 극성 탐지 작업을 하였다. Semantria에서는 긍정(Positive), 부정(Negative), 중립(Neutral)이라는 3가지 분야로 긍정의 최고 점수는 1점, 부정의 최고점수 -1점, 중립은 0.02점~-0.02점 사이에서 구분한다. 극성 탐지는 컴퓨터가 텍스트 안에 있는 긍정적, 부정적인 형태소를 탐지하여 정량화한 뒤 통계적 기법을 적용한다[19]. 본 연구에서는 문장 내에서 형태소의 감성 점수의 총합과 평균을 구해 문장 전체가 긍정적인지 부정적인지 확인을 하였다.
각 화의 평균 감성 점수를 사용하여 웹툰의 연재가 진행됨에 따라 댓글의 오피니언의 변화를 관찰하기 위해 ANOVA 분석을 하여 감정 분포도를 확인하고 시각화를 하였다.
분석은 통계 프로그램인 R의 KoNLP 패키지와 Wordcloud 패키지를 이용하여 형태소 추출 및 워드 클라우드기법(word cloud)분석을 하였다. 문장 간 연관성 분석은 arules와 igraph 패키지를 사용하여 Co-Word 간의 연관관계를 분석하였다. 감성 분석은 LexalyticsⓇ사의 SemantriaⓇ for Excel을 사용하였다. 추출한 감성점수는 SAS 9.4 프로그램(SAS Institute, Cary, NC, USA)을 사용하여 통계분석을 하였다.
연구 결과
댓글의 일반적 특성
본 연구에서 최초 수집한 댓글 수는 20,560건이었고, 데이터 전처리 작업을 통하여 18,117건의 댓글을 대상으로 조사하였다. 매 화마다 독자가 웹툰을 본 후 입력할 수 있는 별점을 살펴보면 대부분 10점 만점에 9점대 후반이었다. 그리고, 1화에서 9.83이었던 것이 마지막 화인 12화에서 9.93으로 증가하였다. 별점 참여자는 107,264명으로 최초 17,439명에서 12화에서는 6,325명으로 감소하였다.
다빈도 형태소 분석
매화 별 댓글 중에서 가장 많이 언급되는 형태소를 분석한 결과 1인칭 2인칭 단어와 조사, 접속사 등을 제외하고 그 외 가장 많이 언급된 상위 20위 형태소는 Table 1과 같다. 1화부터 12화까지 매 화마다 ‘담배’가 가장 많이 언급되었다. 그 외 ‘금연’, ‘사람’, ‘흡연자’, ‘아빠’, ‘제발’, ‘피는’, ‘작가님’ 등의 형태소가 많이 관찰되었다. 그 외 ‘전자담배’, ‘간접흡연’, ‘흡연구역’, ‘담뱃값’, ‘세금’ 등 담배와 관련한 사회적 이슈에 대해서 언급이 되었다. ‘금연’의 경우에는 1화에는 11위이었다가 4화부터는 2-3위에 올라갔으며, ‘아빠’는 연재 초기에는 언급이 없었으나 5화에서부터 10위에 언급되어 11화에서는 2위까지 올라갔다.
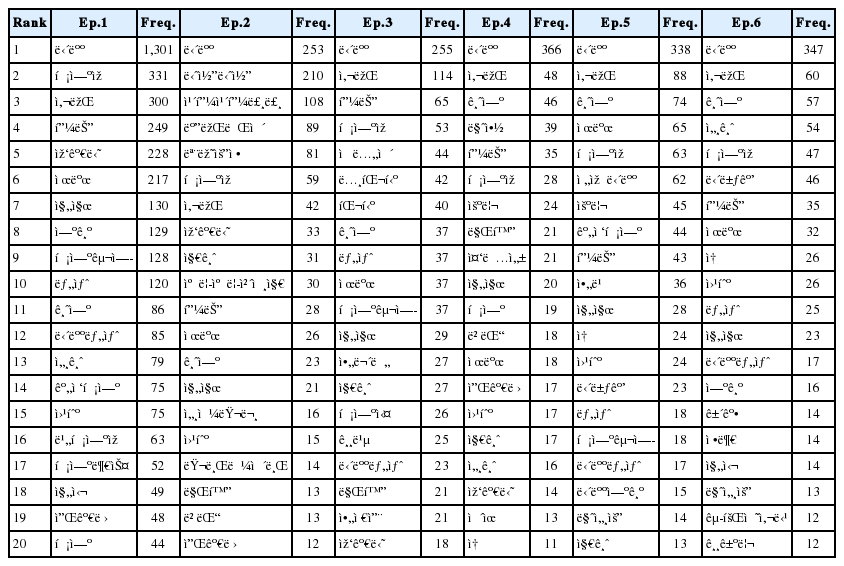
Frequency morpheme of each episode comments (Top 20)
연재 초기에는 담배와 관련된 단어가 많았다면, 연재가 될수록 스토리와 관련된 내용이 관찰되는 것으로 보아 독자들이 작품의 내용을 유심히 보고 그것에 대해서 언급하였다. 마지막 화에서는 작가에게 감사하다는 것과 ‘화이팅’이라는 긍정적인 형태소 ‘알코올뎐’으로 추후 연재해 달라는 요청이 있었다(Table 1).
댓글 형태소 연관성 분석
댓글 형태소의 연관관계를 비교분석하기 위해서 관계도 분석을 하였다. Figure 2는 지지도와 신뢰도 0.01로 했을 때의 연관관계도이다. ‘담배’와 관련된 형태소로서는 ‘흡연’, ‘사람’, ‘냄새’, ‘연기’, ‘금연’, ‘생각’, ‘세금’이었으며 ‘흡연자’와 ‘흡연’ 간의 ‘길거리’라는 형태소로 분석되어 간접흡연에 관한 댓글이 많았다. 관계도의 중심에서 떨어져 있는 ‘자유’, ‘부인’은 작가의 이전 작품으로 작가에 대한 관심이 높은 것을 볼 수 있다.

Association diagram between morphemes (support=0.01, confidence=0.01).
Figure 2를 보면 ‘우리’, ‘아빠’, ‘냄새’, ‘진짜’, ‘담배’, ‘금연’이라는 형태소가 가까이 관찰되는데 댓글을 쓴 독자가 <우리 아빠도 담배 때문에 냄새가 나서 진짜 금연을 했으면 좋겠다.>는 비슷한 댓글이 여러 번 관찰되며 이와 같이 근접한 형태소가 실제 댓글에서도 함께 나오는 것을 확인할 수 있었다. 아래의 표와 같이 R의 arules 패키지를 통해 분석한 ‘아빠’ → ‘금연’의 연관관계는 지지도 0.011, 신뢰도 0.249로 향상도는 1.859이었다. Table 2 지지도는 전체 댓글에서 아빠, 금연이라는 형태소가 함께 발생하는 댓글의 비율이며, 신뢰도는 아빠라는 형태소가 있는 댓글 중에서 금연이라는 형태소가 있는 댓글의 비율이고 향상도는 아빠라는 형태소가 있는 댓글을 쓸 때, 연관 규칙에 의해 금연이라는 형태소가 함께 나오는 비율로 1.859로 1 이상이므로 연관성이 있다고 할 수 있다.

Association figure between morphemes (0.01)
댓글 그래프 기반 소셜 마이닝 기법을 통해 유사 사용자를 클러스터링하고 연관관계를 비교분석하기 위해 관계도 분석을 하였다. 형태소 간의 지지도, 신뢰도, 향상도를 통하여 전체 댓글들이 간접흡연과 관련된 장소에 관한 군집과 흡연으로 인한 피해에 대한 군집, 가족 또는 친구에 대한 군집, 작품과 작가에 대한 군집으로 크게 4개의 군집으로 나눠졌다. 이를 통해 전체적인 댓글 내용과 독자들의 오피니언을 시각적으로 확인할 수 있었다.
감성분석
전처리 작업을 마친 댓글 문장을 통하여 각 화의 댓글 감성분석을 하였다. 댓글의 감성은 한국어의 형용사를 토대로 프로그램 내에 알고리즘화되어 있는 분석 도구를 이용하여 분석을 하였다. 완전 긍정이면 1점, 완전 부정이면 -1점을 주었으며, 중립된 댓글은 실험 결과에 집단이 커짐으로 인해 제거하고, 긍정과 부정인 댓글로 ANOVA 분석을 하여 각 화별 댓글의 감성 분포를 관찰하였다. 중립 감성의 댓글을 제외한 ANOVA 분석을 실시한 결과 12개 화(episodes)에서 통계적 유의성 및 집단 분류에 대한 정확도를 분석한 결과 F-value는 18.20이었고 p-value가 <0.0001로 각 군의 차이는 통계적으로 유의하게 나타났다(Table 3).
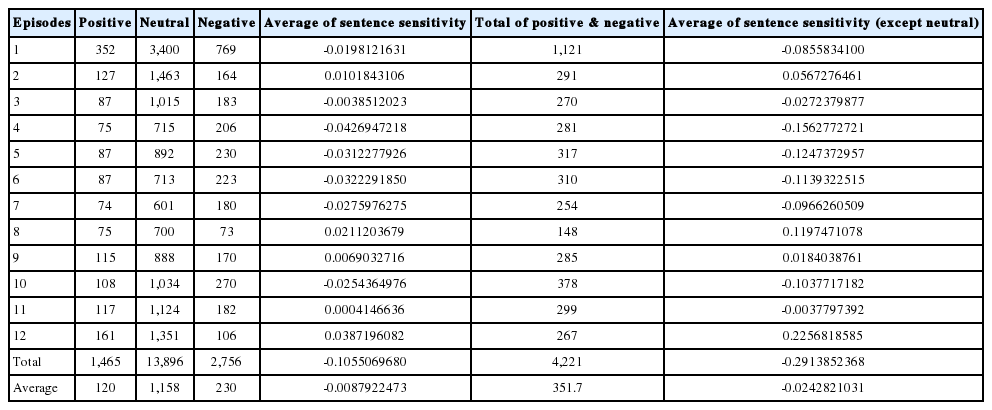
Sentence sensitivity of each episode
각 화별 댓글 문장 감성 분포도를 보면 모두 긍정적인 방향으로 이동하는 것을 확인하였다. 연재 초반에 부정적인 문장이 많았다면 연재가 진행될수록 긍정적인 방향으로 댓글의 감성이 변화가 되었다(Figure 3).

Sentimental distribution chart of positive and negative comment (exclude neutral).
고찰 및 결론
본 연구는 비정형 텍스트 데이터인 웹툰 댓글을 텍스트 마이닝 기법을 적용하여 금연 웹툰 홍보에 대한 반응을 분석하고자 하였다. 이를 위해 20,560개의 댓글을 수집하였고 데이터 전처리 작업을 통해 18,117개의 댓글을 컴퓨터가 이해할 수 있는 요소로 구조화하였으며 텍스트로부터 의미 추출 및 감성 분류를 하였다.
본 연구 결과는 다음과 같은 의의를 제공한다.
첫째, 웹툰 연재가 진행될수록 금연에 관한 관심이 증가하고 본인뿐만 아니라 흡연구역 확대와 같은 정책에도 긍정적인 반응을 보이는 것을 알 수 있다. 금연과 관련된 형태소 빈도는 평균 49.9%인 반면 웹툰에 관련된 형태소 빈도는 18.5%로 나타났다. 특히 담뱃값이 인상된 2015년 1월 첫째 주에 연재된 10화를 보면 ‘금연’과 ‘담배’라는 형태소가 각각 947개와 319개로 빈도가 증가하는 것을 관찰할 수 있었다. 또한 일반적인 금연 관련 단어 외에 높은 빈도를 차지하는 형태소는 ‘연기’, ‘냄새’, ‘담뱃값’, ‘흡연구역’이었다. 독자들이 담배 냄새에 민감하고 담뱃값에 영향을 받으며 흡연구역 규제를 늘리는 것에 대해 관심을 가지는 것을 알 수 있다. Choi [20]의 연구에서 남성 흡연자들이 담배에 대한 지식이 높아지면서 냄새에 민감하고 간접흡연의 유해성과 관련해 관심을 가진다는 결과와 유사하였다.
둘째, 댓글의 내용을 살펴보면 현재 금연 중이라는 댓글과 자신의 금연 방법을 게시해놓았고, 댓글상에서 독자들끼리 서로 소통하는 모습도 관찰되었다. 화장실, 환기구, 아파트, 베란다, 버스정류장 및 길거리 등 장소에 관한 형태소가 관찰되며 간접흡연으로 발생되는 피해를 호소하는 댓글들도 관찰되었다. 이는 댓글이 이용자 간 상호작용을 통해 소통을 즐기는 하나의 커뮤니티가 될 수 있다는 Watanuki [21]의 연구결과를 뒷받침하는 결과이며 금연 커뮤니티로 활용될 수 있다는 점을 보여준다.
셋째, 웹툰 댓글상에서 ‘아빠’, ‘학교’ 등의 단어 빈도수가 높게 나타난 것으로 보아 웹툰의 주요 독자가 청소년이라는 것을 유추할 수 있었다. 청소년의 흡연 문제가 사회적으로 심각한데 청소년들이 관심 있는 웹툰을 통해 홍보를 하는 것이 효과가 있을 것으로 보인다. 여러 카툰 캐릭터로 금연 경고 포스터를 만들어 청소년과 아동들에게 친근한 캐릭터 사용이 금연홍보에 효과적일 수 있을 것이라 판단된다[22]. 아동들에게 웹툰 감상 활동을 통해 정서 지능 향상을 시키는 연구[23]와 중국인 대상으로 웹툰을 활용한 한국어 교육에 대한 연구[24]처럼 웹툰을 활용하여 적은 비용으로 최대한 많은 사람들에게 금연에 대한 홍보를 했다는 점에서 앞으로도 공공 캠페인이나 기업 홍보 등 다양한 분야에서 웹툰이라는 매체를 활용할 수 있을 것이라고 예상된다. 또한 실제 청소년들이 원하는 금연 관련 교육의 방향과 일반 금연 상담 시에 금연에 따른 이득에서 가족의 건강을 강조하는 것이 금연 동기 강화에 중요한 도움이 될 것으로 생각된다.
마지막으로 전처리 작업을 마친 댓글 문장을 통해 긍정, 부정, 중립으로 나누어 분석도구로 감성 분석을 확인한 결과 초기 댓글에는 부정적인 댓글이 관찰되었다면 연재가 진행될수록 긍정적인 댓글이 증가하는 추세가 관찰되었다. ANOVA test를 통해 관찰된 감성 분포도에서도 긍정인 방향으로 변하는 것을 관찰하였다. 이는 웹툰을 본 독자가 연재가 될수록 본 웹툰에 대해서 긍정의 댓글을 표현한 것으로 볼 수 있다. 이는 금연 홍보와 같은 브랜드 웹툰의 단순한 평점뿐만이 아니라 댓글의 텍스트 마이닝과 오피니언 마이닝을 통하여 독자들의 반응 분석과 효과 정도를 성공적으로 측정할 수 있는 유용한 도구가 될 수 있음을 보여준다.
본 연구의 제한점은 아래와 같다.
첫째, 연구 대상인 댓글에 참여한 독자들의 연령대, 성별에 대한 정보를 알 수가 없어서 분석이 제한적으로 이루어졌다. 1화에 비해 12화에는 독자들의 참여 정도가 30% 정도로 감소하는 양상이 관찰되었다. 향후 독자들에 대한 자세한 정보와 지속적인 참여를 이끌어 내도록 보완된다면 보다 자세한 분석이 이루어질 것으로 기대된다.
둘째, 연구에 사용되었던 소프트웨어인 R과 Semantria는 영문을 기초로 개발된 것으로 국내 컴퓨터 전문가들이 일부 한글화를 하였지만 한글의 다양한 변화성에 있어 완벽한 분석 도구로 사용하기에는 아직 어려운 실정이다. 앞으로 텍스트 마이닝, 오피니언 마이닝, 감성분석과 같은 데이터 마이닝에 대한 한글화의 연구가 지속적으로 필요할 것이다.
셋째, 본 연구는 웹툰 독자들이 쓴 전체 댓글을 수집하여 텍스트 마이닝 조사를 한 것으로, 댓글상에서 문법, 띄어쓰기, 맞춤법 등이 되지 않은 상태로 연구하는 데 어려움이 있었다. 이러한 비정형적 텍스트에서는 전처리 작업이 많이 필요하며, 데이터에 대한 전체적인 이해가 반드시 필요할 것으로 생각된다. 전처리 작업을 하는 데 있어 많은 시간이 소요되었고, 인터넷 용어, 욕설, 댓글 순위 놀이, 베스트 댓글이 되기 위한 반복적인 댓글 등록 등에 대한 전처리 작업을 통하여 데이터 질 관리가 필요했다.
위의 한계점에도 불구하고 본 연구에서 활용했던 방법으로 다른 브랜드 웹툰에 대한 연구가 지속적으로 이루어진다면 브랜드 웹툰의 활성화와 금연 홍보에 대한 효율적인 운영에 많은 도움이 될 것이다.
금연에 관해서 날이 갈수록 관심이 많아지며 특히 담뱃값 인상으로 인해서 많은 금연 홍보가 여러 매체를 통해 일반인들에게 노출되고 있다. 본 연구는 그동안 보고 넘겨버렸던 웹툰의 댓글을 통하여 브랜드 웹툰의 성과를 잘 달성하였는지 단어 빈도 분석과 감성 분석을 통하여 분석해보았다. 이전까지 웹툰의 별점과 조회 수, 댓글 수를 통해 웹툰의 효용성을 보았다면 본 연구는 독자들이 남긴 댓글을 분석하여 다빈도 형태소와 형태소 간 상호 연관 관계, 댓글의 감성 분석을 하여 독자들의 반응 분석을 통한 웹툰의 효과를 입증했다는 점에서 의의를 찾을 수 있을 것이다.
Acknowledgements
This research was supported by the Brain Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT & Future Planning (NRF-2015M3C7A1064796).
Notes
No potential conflict of interest relevant to this article was reported.